TheSQLDistinct clause in the SQL Language allows you to remove any repeated data in a column.
Let-s take a look at the following table/query:
select * from customer;
Here are the results from that query:

We have 6 rows and 4 columns in this table, but I only want to look at the customer_company column.
Here is the query to bring back just that column:
select customer_company from customer;
With the following results:

Now, I want to remove the repeated companies. So if you look at -Dell- in the picture above, you will see that it is in there twice.
That is where the -Distinct- clause comes in. Take a look at what happens when I put distinct into the following query:
select distinct customer_company from customer;I get the following results:
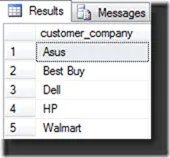
Notice how we only have 5 rows. That is because the extra/repeated Dell row has been removed.
So that is what the distinct clause does, it removes the repeated data elements in a column.
Please post any questions or comments below.